As many of you already know, I am Italian and I am a web marketer.
These two facts made me discover International SEO very soon because -
let's face it - Italy is well-known, but there are not many people in
the world who speak or understand Italian.
If you consider the nature of many Italian companies which rely on the foreign market for a good portion of their revenues, you can understand why SEO and International SEO are essentially synonymous for me and many others European SEOs.
Many small and medium-sized businesses now have the desire to engage in a globalized market. Their motivations are obviously fueled by expanding their business reach, but are also a consequence of the current economic crisis: if your internal market cannot assure an increase from your previous business volume, the natural gateway is trying to conquer new markets.
My Q&A duties as SEOmoz Associate have made me notice the increased interest in International SEO. Rather than seeing a small number of questions community members publicly and privately ask us, we are seeing many questions based on the confusion people still have about the nature of International SEO and how it really works.
In this post, I will try to answer the two main questions above referencing a survey I conducted a few months ago, which (even though it cannot be called definitive) is representative of the common International SEO practices professionals use.
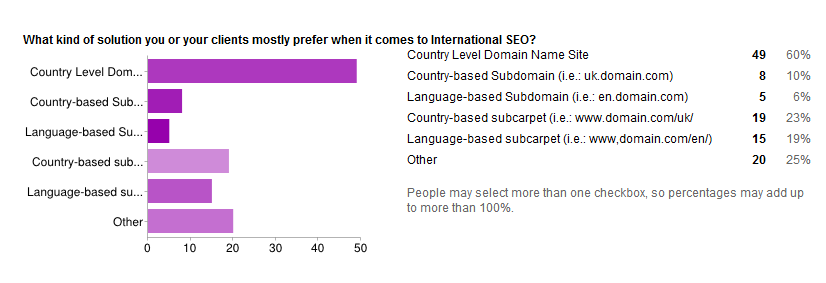 The answers given in the survey clearly show that people seem to prefer
to use country code, top-level domains (ccTlds) against the sub-carpet
option and the sub domain. (I'm still wondering what “other” may mean.)
The answers given in the survey clearly show that people seem to prefer
to use country code, top-level domains (ccTlds) against the sub-carpet
option and the sub domain. (I'm still wondering what “other” may mean.)
The main reason for this choice is the bigger geo-targeting strength of ccTlds. However, this strength is compromised by the fact that you have to create the authority of that kind of site from the ground up through link building.
Does that mean more companies should go for the sub-carpet option? From an SEO point of view, this could be the best choice because you can count on the domain authority of an established domain, and every link earned in any language version will have positive benefits for the others. Sub-carpet domains could be also the best choice if you are targeting a general language market (i.e.: Spanish) and not a specific country (i.e.: Mexico).
However, there are drawbacks in choosing sub-carpet domains:
For instance, it is quite logical that Amazon decided to base its expansion into foreign market using ccTlds. Apart from the SEO benefits, having all the versions of its huge store on one site would have been utterly problematic.
On the other hand, Apple preferred to use the sub-carpet option as its main site does not include the store part, which is in a sub domain (i.e.: store.apple.com/es). Apple chose a purely corporate format for its site, a decision that reflects a precise marketing concept: the site is for showing, amazing, and conquering a customer. Selling is a secondary purpose.
I suggest you to do the same when choosing between a sub-carpet and ccTld domain. Go beyond SEO when you have to choose between these options and understand the business needs of your client and/or company. You will discover there are bigger problems to avoid in doing so.
 This is a classic issue I see in Q&A. Google personally responded to this issue in an older, but still relevant, post on their Webmaster blog:
This is a classic issue I see in Q&A. Google personally responded to this issue in an older, but still relevant, post on their Webmaster blog:
"The server location (through the IP address of the server) is frequently near your users. However, some websites use distributed content delivery networks (CDNs) or are hosted in a country with better webserver infrastructure, so we try not to rely on the server location alone."
Nonetheless, in the case that you are using a CDN, examine where its servers are located and check if one or more are in or close to the countries you are targeting. The reason for this examination is not directly related to SEO, but concerns the Page Speed issue. Page Speed is more of a usability problem, but it has an effect on your site's SEO.
 Finally, don’t confuse local IP with local hosting as you can use a local IP via proxy from your own server. In
certain countries, a hosting solution can be a real pain, and that
drives many companies to host their clients sites in servers located in
another country.
Finally, don’t confuse local IP with local hosting as you can use a local IP via proxy from your own server. In
certain countries, a hosting solution can be a real pain, and that
drives many companies to host their clients sites in servers located in
another country.
Takeaway: do not get obsessed by having a local IP for your ccTld site, as it is now a minor factor.
In case you choose the sub-folder option, another important technical aspect is to create separate sitemaps.xml files for every one of them. Again, common sense, but worth mentioning.
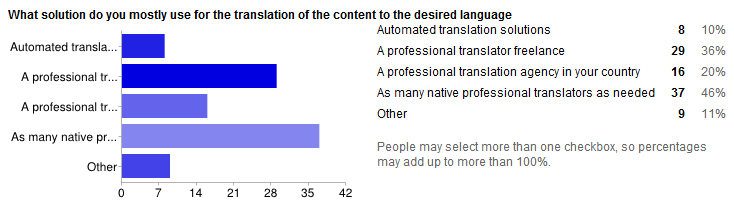 If you are going to do International SEO, the first problem you will have is translating the content of your site in the language of the country you are going to target.
If you are going to do International SEO, the first problem you will have is translating the content of your site in the language of the country you are going to target.
It is common sense to use a professional translator (or a translation agency), but some people lack common sense and tend to rely on:
The first choice is officially deprecated because it is considered (correctly) as a bad quality signal to Google. Even though Google's translator tool was created for this purpose, it seems as if they are sending some mixed messages and I advise you to look elsewhere for translating services.
A professional translation of your content is the best ally for your keyword search.
For example, let's say you want to rank for “car sell” in the Spanish and Latin American market. If you use Google Translate (or Babylon, WordLingo, or Bing Translate), you will have just one of the many variants of that keyword possible all over the Spanish variations map:
When I have to optimize a site for a foreign language, I give the translator a detailed list of keywords in which they will:
Do you think all this is possible using an automatic translator?
A correct translation is one of the most powerful geo-targeting signals a site can have, especially when a language is spoken in more than one country It is an extremely important usability tactic (which is correlated to better conversions), because people tend to trust a vendor who speaks as they speak.
 Other classic geo-targeting signals are the use of local currencies, addresses, and phone numbers. Using them is very common sense, but again, some people don’t excel in that field.
Other classic geo-targeting signals are the use of local currencies, addresses, and phone numbers. Using them is very common sense, but again, some people don’t excel in that field.
However, you may have problems when you target a language all over the world and not a specific country. Obviously you cannot use the local signals described before, because you have the opposite objective. What to do then? I rely on the following steps:
 If you reflect wisely about I have written up to this point, be sure to
notice that "On Page International SEO" is not all that different from
“On Page National SEO”. However, the slight differences arise when we
talk about tagging for multilingual and multi-country sites, and there
is a lot of confusion about this topic (thanks in part to some
contradicting messages Google gave over the last two years).
If you reflect wisely about I have written up to this point, be sure to
notice that "On Page International SEO" is not all that different from
“On Page National SEO”. However, the slight differences arise when we
talk about tagging for multilingual and multi-country sites, and there
is a lot of confusion about this topic (thanks in part to some
contradicting messages Google gave over the last two years).
The geo-targeting tags are needed to avoid showing the incorrect URL in a determined regional Google search. A classic example is seeing a US site outranking a UK site in Google.co.uk, usually due to a stronger page/domain authority. They don’t have any other function than that.
At first sight, its implementation is quite simple:
if Page A (US version) exists also in Page B (Spanish), C (French), and D (German) versions from other countires, no matter if they are in the same domain or different, then on page A you should suggest the last three URLs as the ones Google must show in the SERPs in their respective targeted Googles.
Those tags must be inserted in the <head> section and look like this:
<rel=”alternate” hreflang=”es-ES” href=”http://www.domain.com/es/page-B.html” />
In this line, “es” indicates the language accordingly to the ISO 6391-1 format, and “ES” the country we want to target (in ISO 3166-1 Alpha 2 format).
You can also submit the language version information in your sitemaps. This is the best choice in order to not burden your site code, and it actually works very well, as Peter Handley discusses in this post. Also, they offer pre-existing tools which integrate the rel="alternate" hreflang="x" value in the sitemaps.xml files, as this one by The Media Flow.
Is not so hard, is it? Unfortunately, SEOs had been discouraged by atrocious doubts, especially when their International SEO previewed targeting countries where the same language is spoken.
What is the reason of these doubts? It is the fear for the (substantially) duplicated content those sites (or sub-carpets) tend to have, and the correct use of rel=”canonical”".
For example, in a multilingual site, we have the US American portion of our eCommerce store on www.mysite.com/store/. In www.mysite.com/au/store/ we have the Australian version. Both sell the same products and their product pages are substantially identical.
As we know, duplicated and substantially duplicated content is one of the classic Panda factors. So, does that mean we need to use as canonical of the Australian store pages the American ones? The answer is: no!
Google lists a couple of reasons why this is the case:
Therefore, using canonical to direct to a different URL will cause your users to miss a page with potential useful and important information.
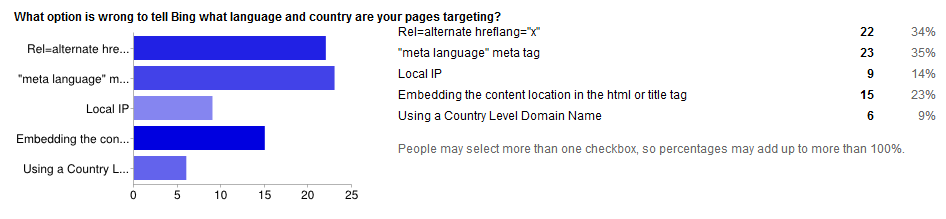 Bing does not use the rel=”alternate” hreflang=”x” markup.
Bing does not use the rel=”alternate” hreflang=”x” markup.
As written by Duane Forrester in this post, Bing relies over a series of signals, the most important being the meta equiv=”content-language” content=”x-X” tag.
So, why is the sum of the budget for all of your International SEO link building campaigns usually smaller than the one of your national market?

Logic should suggest that the first answer (“almost the same…”) was the most common.
The reasons typically used to justify this outcome is that “link building in X is easier” or that “the costs for link building are cheaper." Both justifications are wrong, and here's why:
In fact, those local link builders are the best source to explain what the reality of link building looks like in their countries. For instance, how many of you know that Chinese webmasters tend to prefer a formal outreach contact via email than any other option? I didn't know until I asked.
Modern-day link building does not mean anymore directory submissions, dofollow comments, or forum signatures than it used to, but it has evolved into a more sophisticated art which uses content marketing its fuel and social media as its strongest ally.
Therefore, once you've localized the content of your site accordingly to the culture of the targeted country, you must also localize the content marketing actions you have planned to promote your site with.
Luckily, many SEOs are aware of this need:
 And they usually work with local experts:
And they usually work with local experts:
 If we consider SEO as part of a bigger Inbound Marketing strategy, then
we have to consider the importance Social Media has on our SEO
campaigns (just remember the several correlation studies about social
signals and rankings). So, if you are doing International SEO,
especially in very competitive niches, you must resign yourself to the
idea that you will need a supporting International Social Media
strategy.
If we consider SEO as part of a bigger Inbound Marketing strategy, then
we have to consider the importance Social Media has on our SEO
campaigns (just remember the several correlation studies about social
signals and rankings). So, if you are doing International SEO,
especially in very competitive niches, you must resign yourself to the
idea that you will need a supporting International Social Media
strategy.
Sure, it has some technicalities, but you may need to use them if you want to target other languages spoken in your own country, as Spanish is in the USA. All the rest of your SEO strategy is identical, other than the language used.
All the concepts related to Link Building and Inbound Marketing in International SEO and SEO are the same. The only difference lies in what tactics and what kind of content marketing actions works best from country to country.
What can really make International SEO much more difficult than “classic SEO” is one basic thing: not understanding the culture of the country and people you want to target. Don't make the mistake of having your International sites written by someone like Salvatore, the literally multilingual character of "The Name of Rose" by Umberto Eco.

If you consider the nature of many Italian companies which rely on the foreign market for a good portion of their revenues, you can understand why SEO and International SEO are essentially synonymous for me and many others European SEOs.
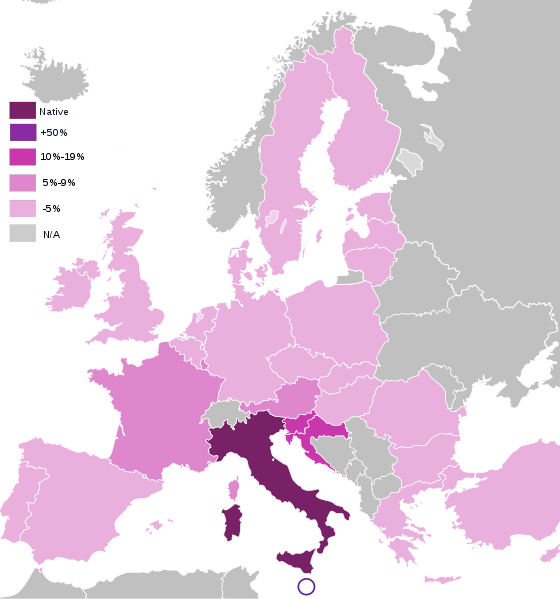
This map explains why I must be an International SEO. Image by: http://www.hu.mtu.edu
This explains my interest in how search engines treat the problems
associated with multi-country and multi-lingual sites. It also
influences my interest in how a company can come in, attack, and conquer
a foreign market. I've seen both interests becoming quite common and
popular in the SEO industry during these last 12 months.Many small and medium-sized businesses now have the desire to engage in a globalized market. Their motivations are obviously fueled by expanding their business reach, but are also a consequence of the current economic crisis: if your internal market cannot assure an increase from your previous business volume, the natural gateway is trying to conquer new markets.
My Q&A duties as SEOmoz Associate have made me notice the increased interest in International SEO. Rather than seeing a small number of questions community members publicly and privately ask us, we are seeing many questions based on the confusion people still have about the nature of International SEO and how it really works.
In this post, I will try to answer the two main questions above referencing a survey I conducted a few months ago, which (even though it cannot be called definitive) is representative of the common International SEO practices professionals use.
What kind of solution is best for International SEO?
The main reason for this choice is the bigger geo-targeting strength of ccTlds. However, this strength is compromised by the fact that you have to create the authority of that kind of site from the ground up through link building.
Does that mean more companies should go for the sub-carpet option? From an SEO point of view, this could be the best choice because you can count on the domain authority of an established domain, and every link earned in any language version will have positive benefits for the others. Sub-carpet domains could be also the best choice if you are targeting a general language market (i.e.: Spanish) and not a specific country (i.e.: Mexico).
However, there are drawbacks in choosing sub-carpet domains:
- Even though a sub-carpets can be geotargeted in Google Webmaster Tools, they seem to have less geotargeting power than a country code, top-level domain.
- In some countries, users prefer to click on a ccTld than on a sub-folder results page because of the trust that is (unconsciously) given to them.
- If any part of your site is flagged for Panda, the entire domain will be penalized. A poorly organized and maintained multilingual/multicountry site may increase this risk exponentially.
For instance, it is quite logical that Amazon decided to base its expansion into foreign market using ccTlds. Apart from the SEO benefits, having all the versions of its huge store on one site would have been utterly problematic.
On the other hand, Apple preferred to use the sub-carpet option as its main site does not include the store part, which is in a sub domain (i.e.: store.apple.com/es). Apple chose a purely corporate format for its site, a decision that reflects a precise marketing concept: the site is for showing, amazing, and conquering a customer. Selling is a secondary purpose.
I suggest you to do the same when choosing between a sub-carpet and ccTld domain. Go beyond SEO when you have to choose between these options and understand the business needs of your client and/or company. You will discover there are bigger problems to avoid in doing so.
The local IP issue and the local hosting paranoia
"The server location (through the IP address of the server) is frequently near your users. However, some websites use distributed content delivery networks (CDNs) or are hosted in a country with better webserver infrastructure, so we try not to rely on the server location alone."
Nonetheless, in the case that you are using a CDN, examine where its servers are located and check if one or more are in or close to the countries you are targeting. The reason for this examination is not directly related to SEO, but concerns the Page Speed issue. Page Speed is more of a usability problem, but it has an effect on your site's SEO.
Takeaway: do not get obsessed by having a local IP for your ccTld site, as it is now a minor factor.
In case you choose the sub-folder option, another important technical aspect is to create separate sitemaps.xml files for every one of them. Again, common sense, but worth mentioning.
The “signals”
It is common sense to use a professional translator (or a translation agency), but some people lack common sense and tend to rely on:
- Automated translation services (especially Google Translate)
- People in-house who happen to know the language the content needs to be translated to
The first choice is officially deprecated because it is considered (correctly) as a bad quality signal to Google. Even though Google's translator tool was created for this purpose, it seems as if they are sending some mixed messages and I advise you to look elsewhere for translating services.
A professional translation of your content is the best ally for your keyword search.
For example, let's say you want to rank for “car sell” in the Spanish and Latin American market. If you use Google Translate (or Babylon, WordLingo, or Bing Translate), you will have just one of the many variants of that keyword possible all over the Spanish variations map:
- Venta de coches (Spain)
- Venta de carros (Mexico)
- Venta de auto (Argentina)
- And so on…
When I have to optimize a site for a foreign language, I give the translator a detailed list of keywords in which they will:
- Translate properly according to the target
- Use in the translations themselves
- Creating a list of keywords with traffic estimations
- Google suggesting “related to my topic” keywords
- Collecting and analyzing Google Trends information for the keywords
- If you copy and paste the translated page (not just the translated keywords list), Adwords will suggest a larger and more sophisticated list of keywords
- Refinement of the initial list of keywords and, if there are changes to make in the translations due to that keywords analysis, asking the translator to revise them.
Do you think all this is possible using an automatic translator?
A correct translation is one of the most powerful geo-targeting signals a site can have, especially when a language is spoken in more than one country It is an extremely important usability tactic (which is correlated to better conversions), because people tend to trust a vendor who speaks as they speak.
However, you may have problems when you target a language all over the world and not a specific country. Obviously you cannot use the local signals described before, because you have the opposite objective. What to do then? I rely on the following steps:
- If the language has variants, try to use an academically standardized translation which is comprehended and accepted in every country that language is spoken.
- You may not have offices in the countries your targeted language is spoken, but you might have a customer care department in that language. Try to “buy” legitimate local phone numbers and redirect them to your real toll-free number, while listing them in your “how to contact us” page on the site.
- Rely more heavily on other signals such as local listings and a balanced link building strategy.
The never ending story of how to implement the rel=”alternate” hreflang=”x” tag
The geo-targeting tags are needed to avoid showing the incorrect URL in a determined regional Google search. A classic example is seeing a US site outranking a UK site in Google.co.uk, usually due to a stronger page/domain authority. They don’t have any other function than that.
At first sight, its implementation is quite simple:
if Page A (US version) exists also in Page B (Spanish), C (French), and D (German) versions from other countires, no matter if they are in the same domain or different, then on page A you should suggest the last three URLs as the ones Google must show in the SERPs in their respective targeted Googles.
Those tags must be inserted in the <head> section and look like this:
<rel=”alternate” hreflang=”es-ES” href=”http://www.domain.com/es/page-B.html” />
In this line, “es” indicates the language accordingly to the ISO 6391-1 format, and “ES” the country we want to target (in ISO 3166-1 Alpha 2 format).
You can also submit the language version information in your sitemaps. This is the best choice in order to not burden your site code, and it actually works very well, as Peter Handley discusses in this post. Also, they offer pre-existing tools which integrate the rel="alternate" hreflang="x" value in the sitemaps.xml files, as this one by The Media Flow.
Is not so hard, is it? Unfortunately, SEOs had been discouraged by atrocious doubts, especially when their International SEO previewed targeting countries where the same language is spoken.
What is the reason of these doubts? It is the fear for the (substantially) duplicated content those sites (or sub-carpets) tend to have, and the correct use of rel=”canonical”".
For example, in a multilingual site, we have the US American portion of our eCommerce store on www.mysite.com/store/. In www.mysite.com/au/store/ we have the Australian version. Both sell the same products and their product pages are substantially identical.
As we know, duplicated and substantially duplicated content is one of the classic Panda factors. So, does that mean we need to use as canonical of the Australian store pages the American ones? The answer is: no!
Google lists a couple of reasons why this is the case:
- The rel=”canonical” should show a different URL than the one self referential only if the page is an exact duplicated content of the “canonical” one.
- Product pages are not exact duplicates because they have slights differences like currencies, contact phone numbers, addresses, and – if you localized also the text – in the spelling of some words.
Therefore, using canonical to direct to a different URL will cause your users to miss a page with potential useful and important information.
What about Bing?
As written by Duane Forrester in this post, Bing relies over a series of signals, the most important being the meta equiv=”content-language” content=”x-X” tag.
Inbound Marketing, Link Building, and International SEO
Now we have our multilingual/multi-country site optimized, but even if we choose the sub-carpet way in order to have a first boost from the existing domain authority of the site and the flow of its link equity, we still must increase the authority and trust of the language/country targeted sub-carpet in order to earn visibility in the SERPs. This need becomes even more urgent if we decided the ccTld option.So, why is the sum of the budget for all of your International SEO link building campaigns usually smaller than the one of your national market?
The reasons typically used to justify this outcome is that “link building in X is easier” or that “the costs for link building are cheaper." Both justifications are wrong, and here's why:
- To do link building in every country is harder than it seems. Take Italy, for instance. is not so easy as you can imagine. In Italy, the concept of guest blogging is still quite “avant-guarde.”
- To do #RCS which will earn your site links, social shares and brand visibility is not cheap. In Italy (I'm using my home country as an example, again), the average price for a good infographic (not interactive nor video) ranges between $1,000-1,200 US dollars.
In fact, those local link builders are the best source to explain what the reality of link building looks like in their countries. For instance, how many of you know that Chinese webmasters tend to prefer a formal outreach contact via email than any other option? I didn't know until I asked.
Modern-day link building does not mean anymore directory submissions, dofollow comments, or forum signatures than it used to, but it has evolved into a more sophisticated art which uses content marketing its fuel and social media as its strongest ally.
Therefore, once you've localized the content of your site accordingly to the culture of the targeted country, you must also localize the content marketing actions you have planned to promote your site with.
Luckily, many SEOs are aware of this need:
Conclusions
International SEO for Google and Bing is SEO, no questions asked. It is also not substantially different than the SEO you do for your national market site.Sure, it has some technicalities, but you may need to use them if you want to target other languages spoken in your own country, as Spanish is in the USA. All the rest of your SEO strategy is identical, other than the language used.
All the concepts related to Link Building and Inbound Marketing in International SEO and SEO are the same. The only difference lies in what tactics and what kind of content marketing actions works best from country to country.
What can really make International SEO much more difficult than “classic SEO” is one basic thing: not understanding the culture of the country and people you want to target. Don't make the mistake of having your International sites written by someone like Salvatore, the literally multilingual character of "The Name of Rose" by Umberto Eco.









